记录折腾の日常
一、前言
本次使用由GitHub【1】大佬RVC-boss【2】制作的开源【4】声线检索替换技术,它是一款易于使用的AI 翻唱工具【5】,AI变声器【6】
为什么选择RVC?
RVC的操作对于新手较为友好。同时官方制作的有一键整合包【8】,可以跳过繁琐的配置环境过程。RVC的推理【9】与训练【10】模型界面,官方都提供了可视化操作界面,支持一键傻瓜式训练模型。
二、准备
数据集的准备与清洗
先从网络上搜集目标人物10分钟左右的音频素材,要求:情绪丰富、杂音少、声音清晰。不要闷闷的。注意将目标人物的音频素材转换为WAV格式【11】(无损)。
准备好数据集【12】之后就是对数据集的进一步处理,这里我推荐使用The Ultimate Vocal Remover Application(可能因网络因素导致下载过慢,当然此处也提供网盘下载地址)对素材中的杂音进行进一步处理,以下是常用的处理步骤:
网盘链接: https://pan.baidu.com/s/1Bs6W7h0IUvdMNFZfNytw0Q?pwd=e7ag 提取码: e7ag
选择你已经处理好的素材文件,首选选中“MDX-NET【13】”模型种类,并勾选“GPU Conversion【14】”,在“CHOOSE MDX-NET MODEL”中选择“MDX23C-InstVoc HQ【15】”,之后点击“Start Processing”,接着选择“VR Architecture【16】”模型种类,接着选用UVR-De-Echo-Normal【17】 UVR-De-Echo-Aggressive【18】 UVR-De-Echo-Dereverb【19】三种模型其一去除混响。依旧点击“Strat Processing”以上操作过程中的参数保持默认即可。
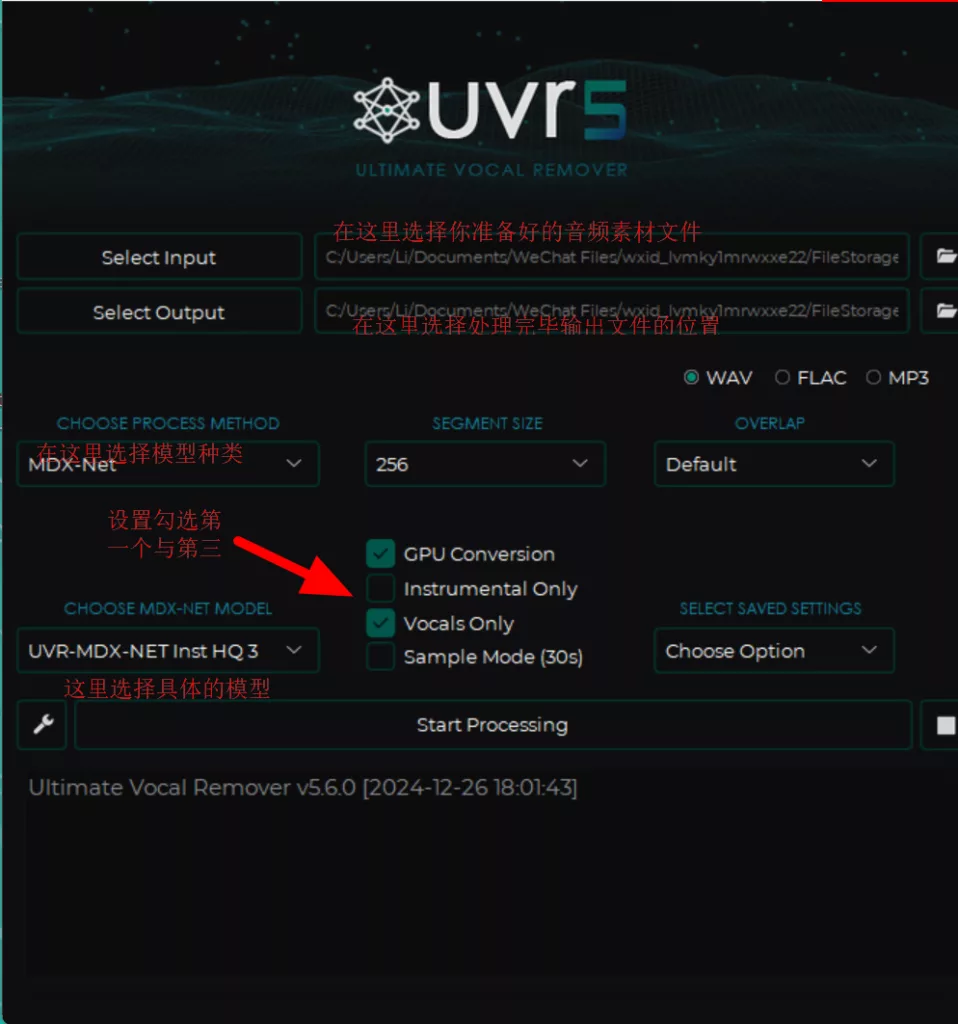
一般情况下,数据集经过以上步骤处理之后都会变得相对较为干净。
整合包的下载
这里提供官方的一键整合包下载地址:
链接: https://pan.baidu.com/s/1Vyj_pSf5EDXpZyRYyorCVg?pwd=i72q 提取码: i72q
根据你的显卡类型下载相应版本,AMD显卡【21】或者英伟达显卡【22】
下载之后解压到一个你新建的文件夹内。
三、模型的训练
首先双击文件夹内的go-web.bat【23】文件,弹出一个弹窗选择允许Python【24】访问网络。
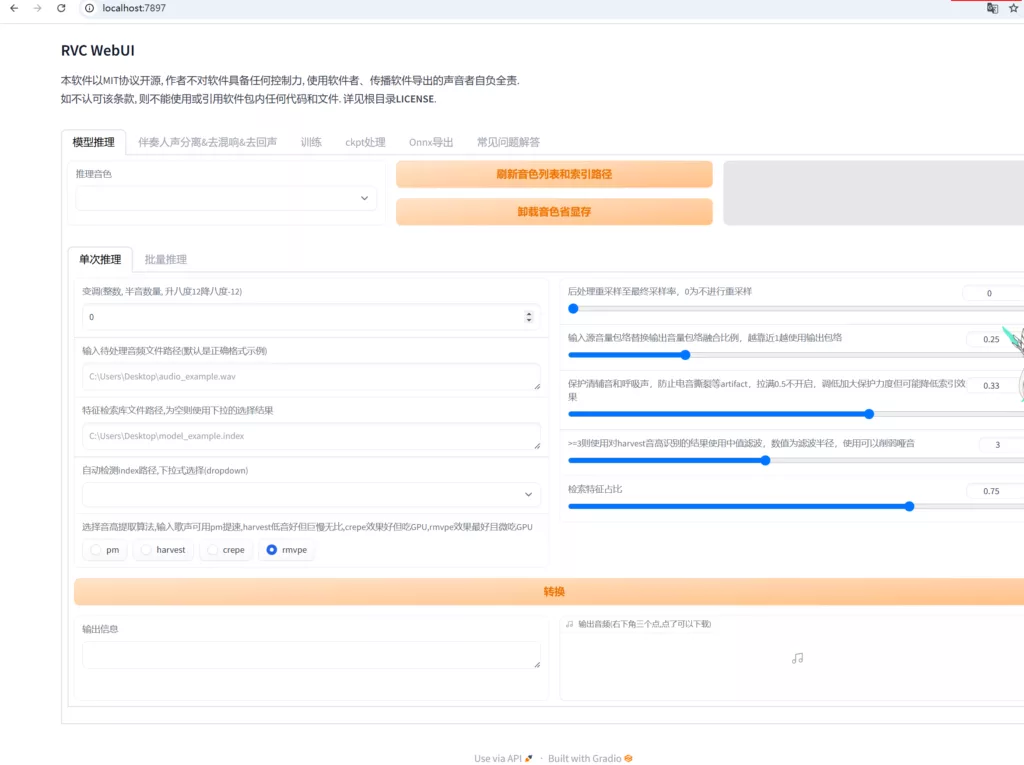
弹出如上图所示的webui界面,选择第三个选项卡(训练)按照如下图配置填写。
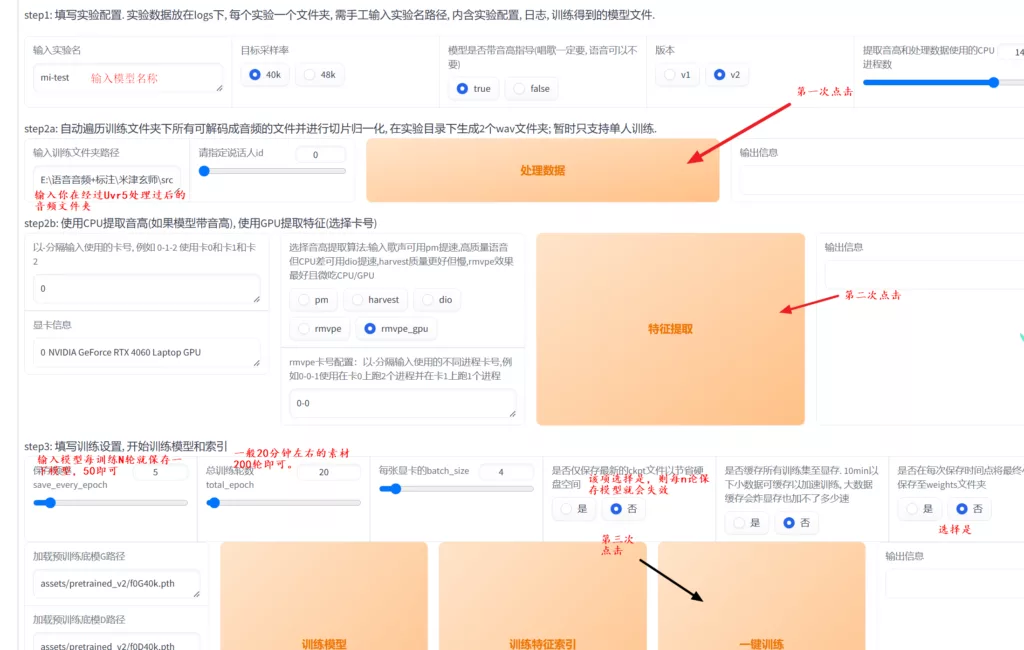
在CMD窗口等待训练完成(黑框框),没有新的epoch【25】轮次出现即可。
之后可以选择第一个选项卡,进行推理。(AI翻唱制作【26】)
模型默认的保存文件夹在.../RVC1006Nvidia\assets\weights
四、虚拟声卡的配置(变声器适用)
先前往https://voicemeeter.com/,选择STANDARD版本下载,安装打开并留存到后台
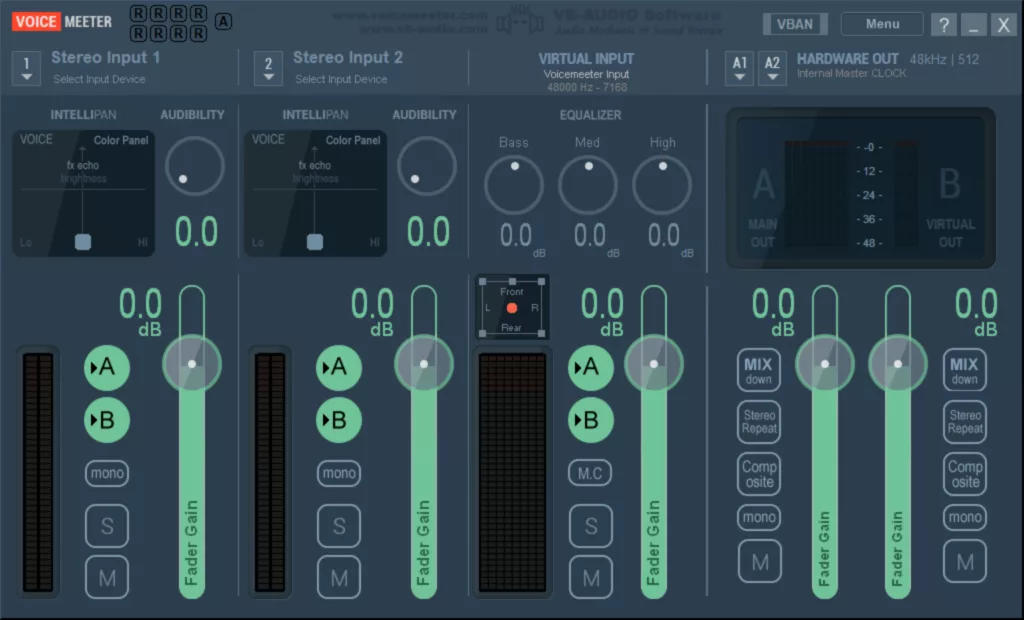
在系统声音设置中按如下设置
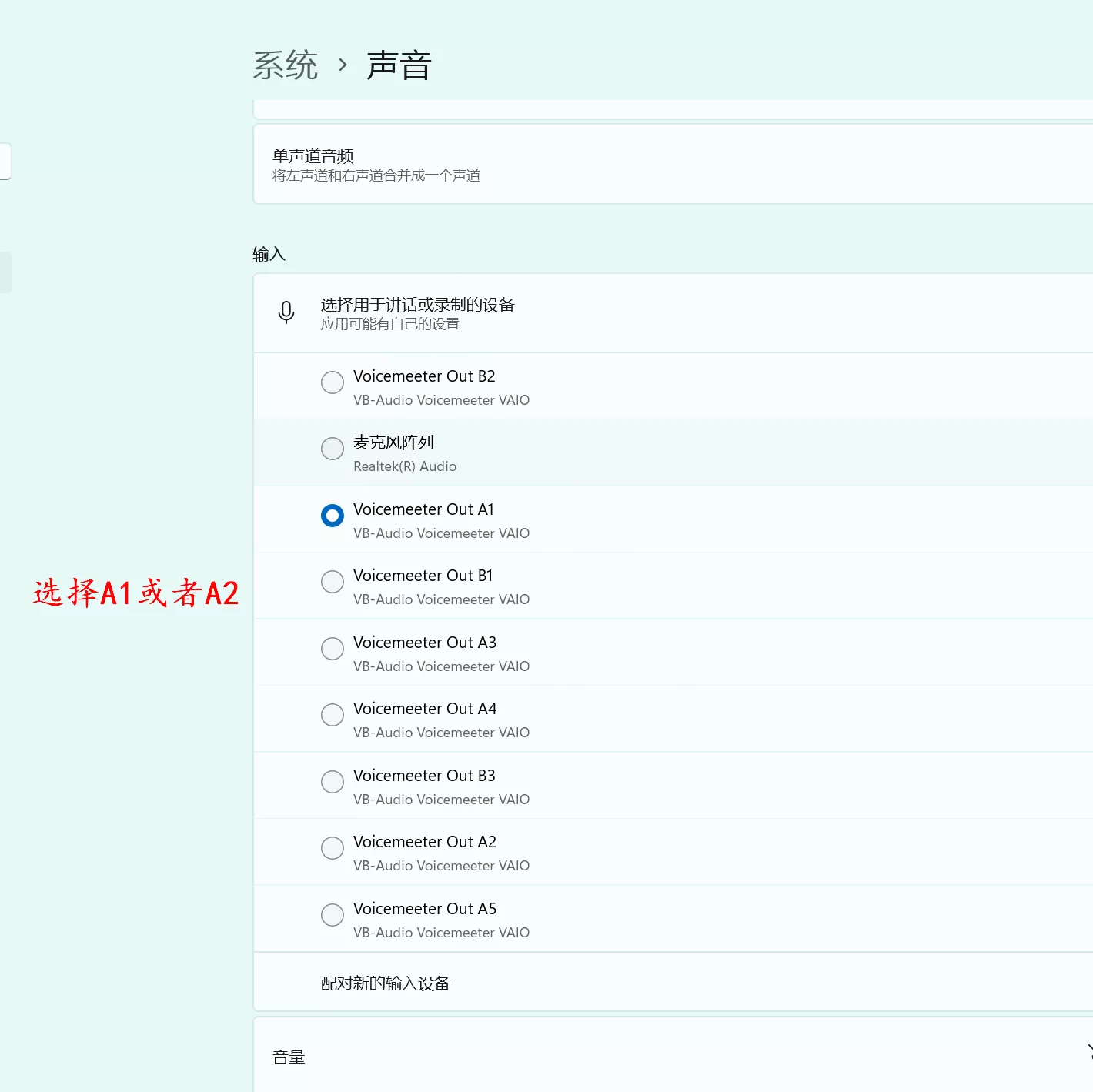
关闭cmd黑框框,双击RVC1006Nvidia根目录下的go-realtime-gui.bat【28】。出现如下gui,按照下图配置
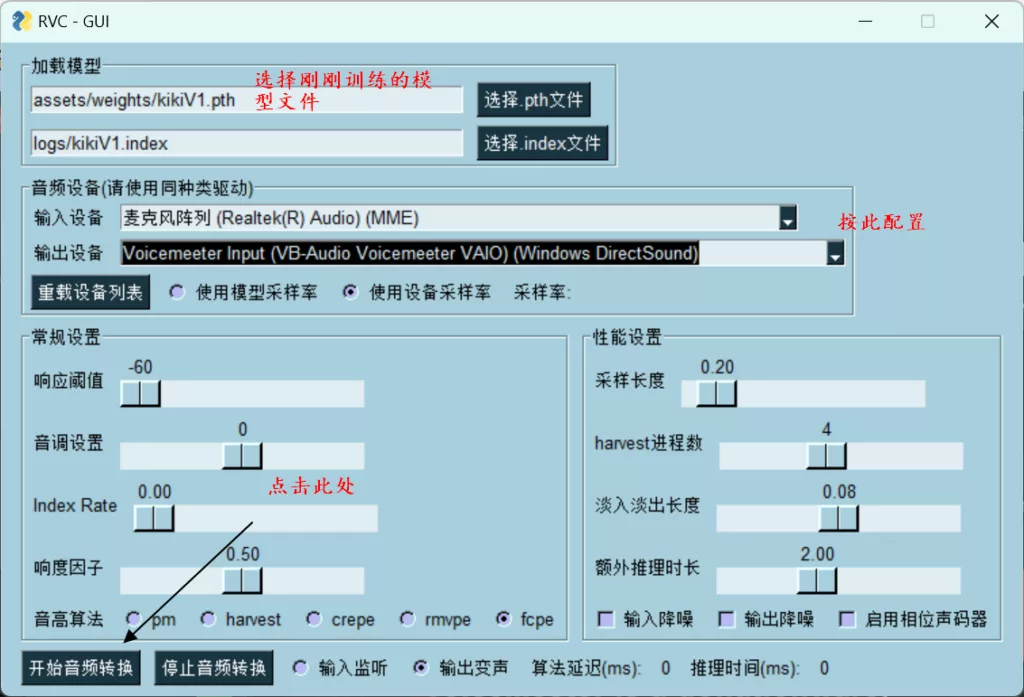
至此,变声教程到此结束。
如果点击开始音频转换,提示未响应。请切换至以下版本
链接: https://pan.baidu.com/s/1N2yheyWo8i91JgRcn5mU0w?pwd=58e7 提取码: 58e7
Comments 5 条评论
更新下载地址123网盘不限速,下载0604版本
www.123pan.com/s/5tIqVv-DjNcv.html
听听你的
感谢李大帅哥

 送来的福利
送来的福利 


真的很感谢博主大大


 可以用奶狗变声器和他打游戏了
可以用奶狗变声器和他打游戏了 
接
